NeurIPS 2022
|
|
|
|
|
|
|

|
|
|
|
|
|
|
Semantic understanding of videos is a key challenge for machine vision and artificial intelligence.
It is intuitive that video models should benefit from incorporating scene structure,
e.g., the objects that appear in a video, their attributes, and the way they interact.
In fact, several works have shown that such ``object-centric'' models perform well on tasks such as action recognition.
However, most of these models require ground-truth structured annotations of video during training.
This is clearly very costly, time-consuming, and not scalable.
This begs the question, could we still benefit from scene structure in a less costly way?
A possible direction is to explore methods that would only require sparsely annotated frames within a downstream video domain.
Moreover, when it comes to structured annotations of static images,
there are numerous datasets with annotations such as boxes, visual relationships, attributes, and segmentations.
Since we can not always expect to have annotated images that perfect align with our downstream video task,
how can these resources be used to build better video models?
In this work, we propose such an approach,
which is particularly well suited for transformer architectures and offers an effective mechanism to leverage image structure to improve video transformers.
Our approach SViT learns a structured shared representation that arises from the interaction between the two modalities of images and videos. We consider the setting where the main goal is to learn video understanding downstream tasks while leveraging structured image data. In this paper, we focus on the following video tasks: action recognition and object state classification & localization. In training, we assume that we have access to task-specific video labels and structured scene annotations for images, Hand-Object Graphs. Based on the structured representations obtained by using the object tokens and regularized by the Frame-Clip Consistency loss. the inference is performed only for the downstream video task without explicitly using the structured image annotations.
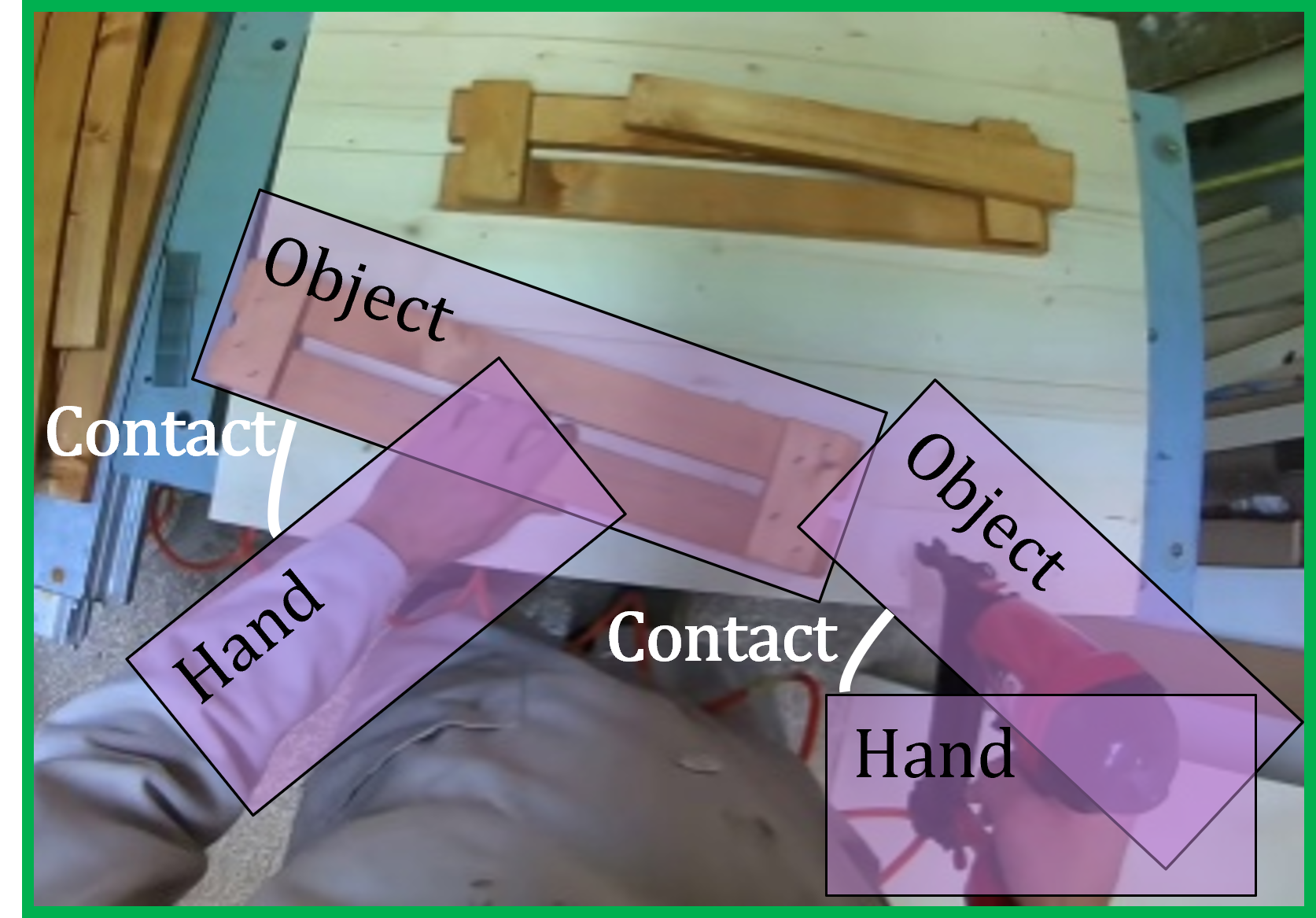
As mentioned above, our motivation is to bring scene structure from still images into video. In order to achieve this, one component of this work is the construction of a semantic representation of the interactions between the hands and objects in the scene. Specifically, we propose to use a graph-structure we Hand-Object Graph (HAOG). The nodes of the HAOG represent two hands and two objects with their locations, whereas the edges correspond to physical properties such as contact/no contact.
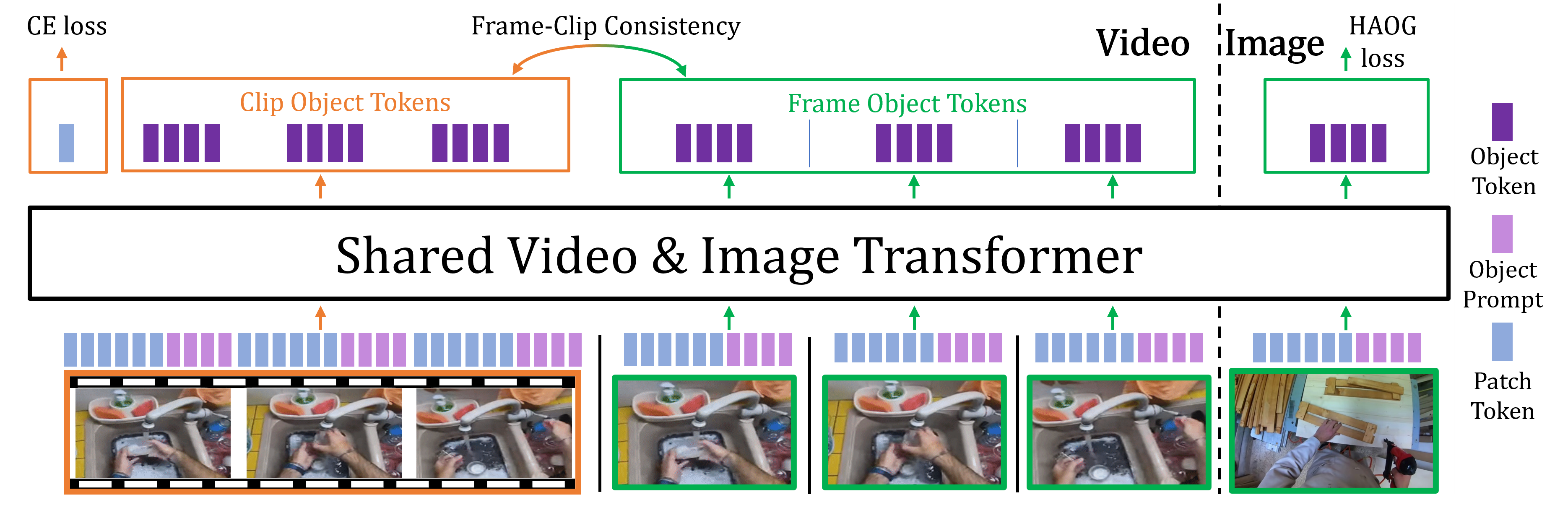
Our shared video & image transformer model processes two different types of tokens: standard patch tokens from the images and videos (blue) and the object prompts (purple), that are transformed into object tokens (purple) in the output. During training, the object tokens (purple) are trained to predict the HAOG for still images. For video frames that have no HAOG annotation, we use our ``Frame-Clip'' loss to ensure consistency between the ``frame object tokens'' (resulting from processing the frames separately) and the ``clip object tokens'' (resulting from processing the frame as part of the video). Last, the final video downstream task prediction results from applying a video downstream task head on the average of the patch tokens in the transformer output (after they have interacted with the clip object tokens (purple).
 |
Elad Ben-Avraham, Roei Herzig, Karttikeya Mangalam, Amir Bar, Leonid Karlinsky, Anna Rohrbach, Trevor Darrell, Amir Globerson Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens Hosted on arXiv |
Related WorksOur work builds and borrows code from MViT. If you found our work helpful, consider citing MViT as well. |
![[SViT Framework Animated]](https://eladb3.github.io/SViT/data/figures/VID7_break.gif){kind=link}